Kaldi - 开源语音识别工具
当前工具是最新版本
语音识别
提供高质量的语音识别功能,支持多种语言和口音,准确将语音转换为文本。
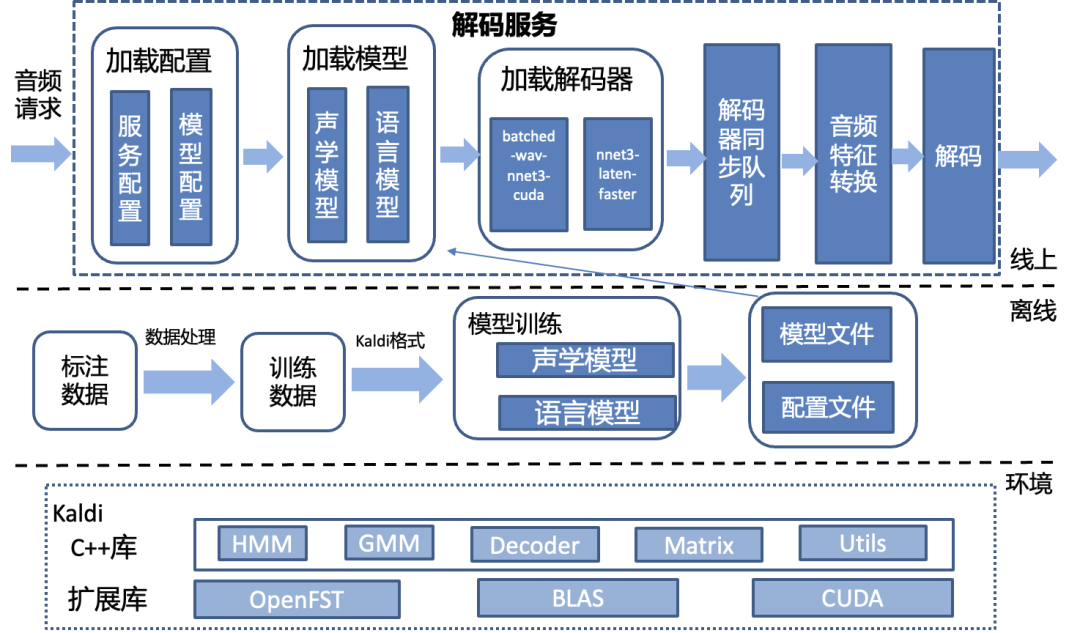
语音转文字
支持将音频文件转换为文本,方便您快速获取音频内容的文字版本,提高工作效率。
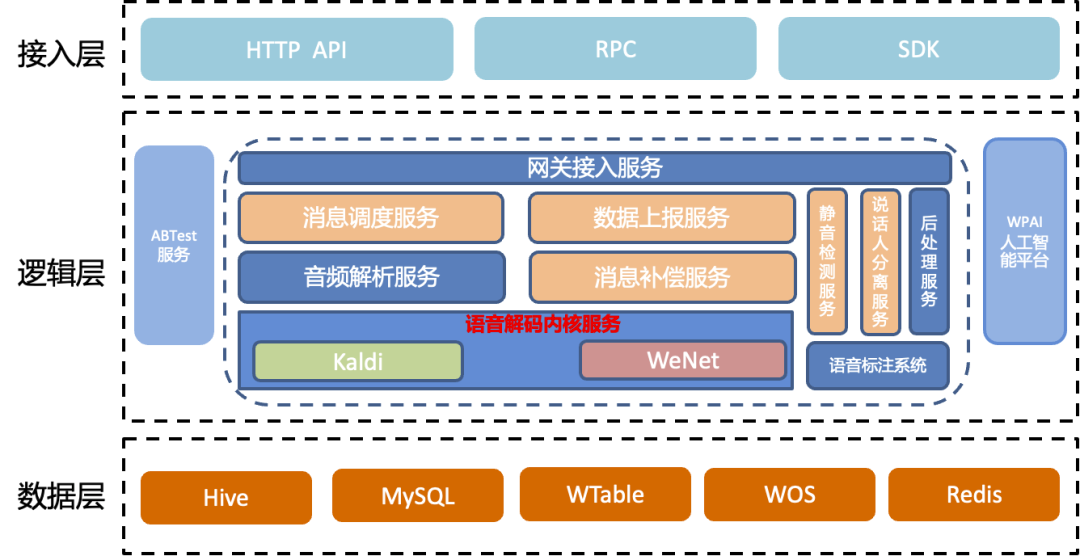
语音处理
提供丰富的语音处理功能,包括噪声抑制、语音增强、语速调整等,提高语音质量。
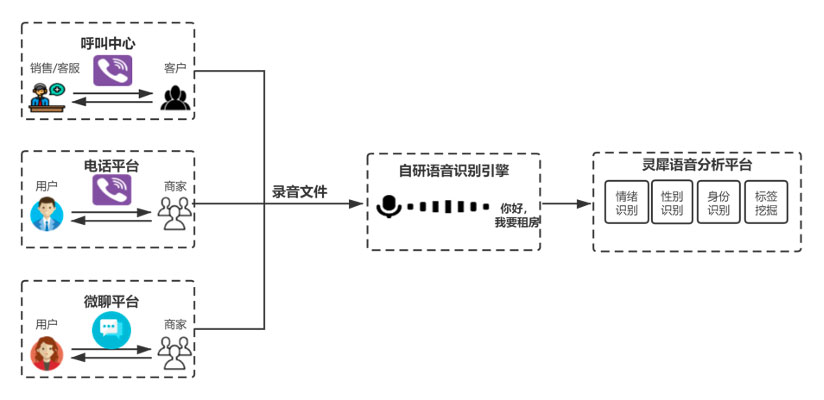
多语言支持
支持多种语言的语音识别,包括中文、英文、日语、法语等,满足不同语言环境的需求。
实时识别
支持实时语音识别功能,可用于会议记录、语音助手等场景,实现实时语音转文字。

自定义模型
支持自定义语音识别模型,可根据特定领域的语音数据进行训练,提高识别准确率。
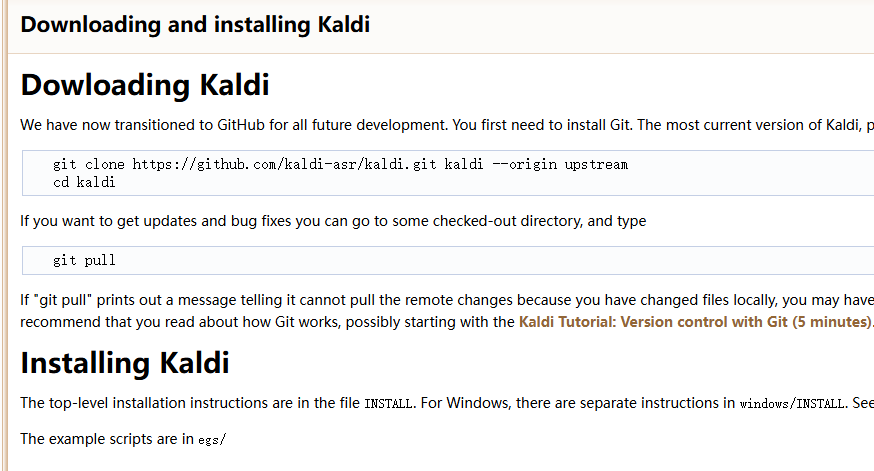
Windows平台支持
专为Windows平台优化,提供稳定的性能和良好的用户体验,让您在Windows环境中轻松使用语音识别功能。